SwiftLM
Fine-tuned a 7B-parameter LLM with QLoRA to generate expert-level Swift code—trained on a single L4 GPU and shipped to HuggingFace.
- Industry
- — AI / ML, Swift, LLM Fine-Tuning
Tools & technologies
The Problem
General-purpose LLMs don't know modern Swift. Suggestions are outdated, unsafe, or just wrong—and they live in the cloud. Fine-tune a 7B model on curated Swift data. Run it locally. Zero cloud round-trips.
Step 2 — Process
Process & Approach
Key Challenges Overcome
Challenge 1
Training a 7B-parameter model on a single L4 GPU without running out of VRAM or sacrificing meaningful learning.
Solution
Combined 4-bit NF4 quantization (bitsandbytes) with QLoRA (rank 16, targeting q_proj and v_proj only) and gradient accumulation of 4. This reduced the active parameter footprint to ~5M trainable weights while keeping the effective batch size large enough for stable gradients—making the full training run feasible in under an hour.
Challenge 2
Exporting a dynamic transformer model to a static ONNX graph without breaking inference.
Solution
Disabled KV-caching (`use_cache = False`) before export and used PyTorch's Dynamo export path, which supports complex operators and dynamic axes. Post-export verification with onnxruntime confirmed logit shape and numerical integrity before publishing the GGUF build.
Environment & Initialization
The environment uses a modern AI stack centered on PyTorch Lightning for training orchestration and bitsandbytes for memory-efficient quantization. L4 GPU optimization was the first configuration decision: setting matmul precision to `high` maximizes hardware utilization on the L4's tensor cores. Key dependencies—lightning, transformers, peft, bitsandbytes, and onnxruntime-gpu—were locked to ensure reproducible training runs across Colab sessions.
Dataset Engineering
5,602 high-quality, curated Swift examples were assembled and transformed into a conversational format compatible with Qwen's internal instruction-following architecture. Chat templates convert JSONL `prompt` and `response` columns into the `<|im_start|>` and `<|im_end|>` format the base model expects. Tokenization is configured with a 512-token sequence length, truncation, and padding. DataLoader is set to a batch size of 2 with shuffled training samples to prevent ordering artifacts.
QLoRA Training Architecture
The model is fine-tuned using Quantized Low-Rank Adaptation (QLoRA), which enables training a 7B-parameter model on a single GPU with limited VRAM. The base model is loaded in nf4 4-bit format with bfloat16 compute dtypes. LoRA is applied with rank 16 and alpha 32 targeting the attention layers (`q_proj` and `v_proj`). The optimizer is PagedAdamW8bit combined with a Cosine Schedule with Warmup over 100 warmup steps—chosen for stable convergence on this dataset size.
Training Execution & Persistence
Training ran on a Google Colab L4 GPU via the Lightning Trainer with bf16-mixed precision for improved speed and stability. Gradient accumulation of 4 simulates a larger effective batch size while keeping VRAM usage bounded. 2,801 steps covered the full dataset across one epoch in approximately 51 minutes at 0.91 iterations per second—near-optimal for a single L4. Only the lightweight LoRA adapters and tokenizer configuration are saved as checkpoints, making versioning and deployment straightforward.
Production Merging & ONNX Export
Moving to production requires merging the learned adapters into the base weights and exporting to a static graph. `merge_and_unload()` folds the adapter weights in, `use_cache` is set to False to prevent the model's dynamic KV-caching from breaking the static ONNX graph, and the model is set to eval mode. Dynamo export via `torch.onnx.export(dynamo=True)` handles complex operators and dynamic axes for batch size and sequence length. Post-export, the model is verified with onnxruntime to confirm output logits maintain correct shape and mathematical integrity.
Local Inference via LM Studio
With the GGUF build published to HuggingFace, I loaded the model locally in LM Studio with GPU Offload set to Max—fully leveraging Apple Silicon's Metal backend for low-latency inference without any cloud round-trip. A custom system prompt ('You are a Senior iOS Architect specializing in clean, safe, and modern Swift code.') keeps the model in the right lane for every completion. From there, LM Studio's built-in OpenAI-compatible local server (default: http://localhost:1234) made it trivial to connect the model directly to Cursor: adding the endpoint as a custom OpenAI API in Cursor Settings means fine-tuned Swift suggestions appear inline in the editor, indistinguishable from any other model—except these know modern Swift deeply.
Final design
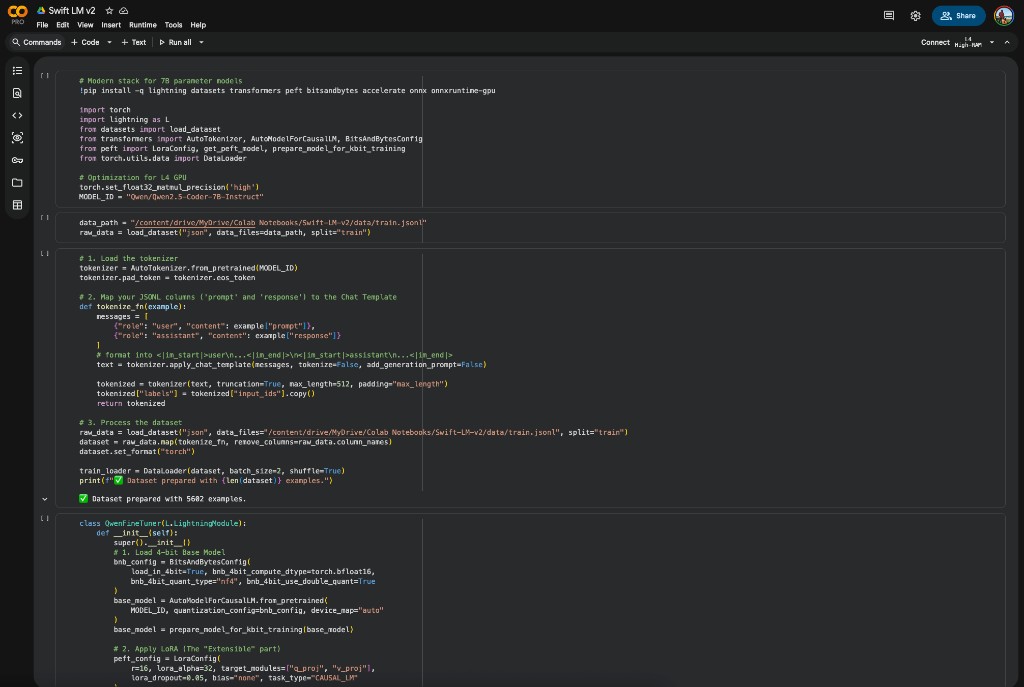
Google Colab training pipeline (left) · SwiftLM running locally in LM Studio via the fine-tuned GGUF (right).
Step 3 — Outcome
Outcome & Reflection
Results & Impact
- ✓50+ downloads on HuggingFace since publishing.
- ✓Final training loss of 0.369—in the Goldilocks zone between memorization (too low) and under-learning (too high), indicating the model generalized Swift patterns rather than memorizing examples.
- ✓Only 5M out of 4.4B parameters were trained, confirming the QLoRA strategy worked as intended and kept the full run under 51 minutes on a single L4 GPU.
- ✓0.91 iterations per second—near-optimal hardware utilization with no significant bottlenecks from the data pipeline.
- ✓Published GGUF build on HuggingFace, loadable in LM Studio with GPU offload for local Apple Silicon inference.
Reflections & Lessons Learned
- •Dataset quality beats dataset quantity: 5,602 curated Swift examples outperformed what a larger but noisier corpus would have produced—the loss curve showed steady, controlled descent with no spikes.
- •PEFT is the right lever for domain adaptation: QLoRA let me surgically update the model's Swift knowledge without touching its general reasoning capabilities—a 7B model fine-tuned this way punches well above its weight.
- •The export pipeline is as important as training: getting from LoRA adapters to a production-ready ONNX graph requires careful sequencing (merge → disable cache → eval mode → Dynamo export → verify)—each step matters.
Future Improvements
Expand the dataset to 15K+ examples covering more SwiftUI edge cases, async/await patterns, and Testing (XCTest, Swift Testing framework).
Train for 2–3 epochs with early stopping on a held-out validation set to squeeze additional performance without overfitting.
Explore direct Core ML export for on-device inference in iOS apps without needing a local server.
My Cross-Functional Impact
Product Perspective
- ▸Scoped the training objective to a specific, underserved niche (modern Swift on Apple Silicon) and validated the gap with real developer pain points.
- ▸Chose GGUF + LM Studio as the deployment target to make the model immediately usable by iOS developers without infrastructure overhead—connect it to Cursor via the local OpenAI-compatible server and get fine-tuned Swift suggestions inline, no cloud required.
Design Perspective
- ▸Designed the dataset schema and chat template format to align with the model's instruction-following architecture.
- ▸Structured the HuggingFace model card for clarity—training details, results interpretation, and usage instructions for developers of different backgrounds.
Engineering Perspective
- ▸Implemented the full training pipeline: QLoRA configuration, PyTorch Lightning orchestration, bf16-mixed precision, and gradient accumulation.
- ▸Built the production export workflow: adapter merging, ONNX Dynamo export with dynamic axes, and onnxruntime inference verification.
Related projects
Vy by Vercept
Senior Product Designer & Engineer
Leverages VyUI to control your computer (Vision AI).
ClawFi
Indie Developer
Bot-native market intelligence. Bots read context and consensus, write observations and signals.
Ollie AAC
Founder/CEO
AI-powered augmentative and alternative communication platform on iPhone & iPad.